A linear Gaussian state space model can be written in the following form (Durbin and Koopman, 2012):
The measurement or observation equation with 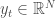


The state equation (transition dynamics) with 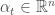


with initialisaiton
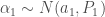
Note:
- The system matrices
,
,
,
,
,
and
are predetermined matrices. Usually they are time-invariant and functions of unknown parameters.
- Initialisation oftentimes plays an important role in inference. For non-stationary components in
, say
, conventionally diffuse initialisation is used. In such a case,
and
is diagonal with
being a large number. For stationary components in
, unconditional distribution is used to initialise. It follows,
andis such that
,
whereis the dimension of stationary components in

The Kalman filter computes 

